本帖最后由 hasea 于 2014-1-31 10:25 AM 编辑
大过年的,再发篇文章。
图的最短路径算法中,常见有Dijkstra、Floyd、A*算法。Floyd的算法复杂度比较高,只计算两点路径的话划不来,A*算法的估价函数在这种地图模式中很难使用一种有效的估值方式。基本只有Dijkstra算法可用。这个算法的时间复杂度是n^2。使用Dijkstra算法从两边同时计算也能提高计算效率。 假设按照Dijkstra算法,上千个房间记录,计算规模就在数百万次。这应该还是比较大的压力的。曾经听说过有些寻路计算耗时数秒,这是非常恐怖的。为了提升寻路效率,我设计了两种寻路算法:1、在数据表中预先计算和记录支路位置情况,然后根据支路位置计算路径。2、分城市直接使用Dijkstra算法计算。 这里主要说的是第一个算法。先随机设定一个预遍历起始点,通过预遍历,标记支路出口和每个房间的最近支路房间。寻路的时候先计算非支路节点列表,然后再用Dijkstra算法计算各个回路连接节点的最短路径。这样应该可以减少大量的计算量。
支路出口 的意思是说从一个出口进去后,想要回到当前房间只能通过从进去的出口返回。 最近支路房间 是指从起始预遍历点出发,只有一个出口到达当前房间最近房间。
计算原理: 第一部分:预遍历。标记每个房间最近的非分支房间,标记每个出口是否支路。这部分数据以后会保存在数据表中。
上图是预遍历的原理。假设以右边第一个节点开始,按红色虚线路径遍历数据。 - 建立一个栈stack来存放遍历过的节点数据和交点结果。
- 每次遍历到新节点时都在该节点中增加一个增长的记录数字标识。则会产生如上图数字所示的数字标识记录。
- 如果遇到已经遍历的节点,则把遇到的相交节点值记入stack传回下个房间。如图11->5,14->3。
- 当前面所有房间都遍历完的时候,每个节点按顺序从stack中移除,并把前面已得到的相交节点值传回最后的stack值中。
- 一个节点可能接到到两个出口传回来的相交节点结果。如图12->10。当从12返回10时,10中应该同时接收有3,5这两个相交点作为结果。
- 当遍历重新返回移动到5节点时,结果中的5被移除掉,当返回到3节点时,结果中的3被移除掉。
- 当stack中存储的结果为0时,说明当前房间是支路房间。如果前面房间是支路房间,遍历设置前面的支路房间都为此房间id。并且设置此路径的通路状态为1(非通路).
第二部分:寻路。先分别检出开始和结束房间的非分支房间记录到起始预遍历点,然后合并开始和结束位置的非分支房间记录形成节点房间列表,最后使用Dijkstra算法计算不相邻节点房间之间的路径。 1、分别从开始房间和结束房间开始检索出到起始预遍历点的非支路节点列表。如下图,黄色和绿色的三角形分别代表起始房间和结束房间的非支路节点列表。
2、合并开始和结束房间的非支路节点,变成如下图所示的节点列表。
3、现在只剩下一些主要节点,一些无关的分支路节点可以都可以通过预遍历的数据判断为无效路径,如上图的虚线部分可以被去除。这样只要判断如图A-B,C-D的最短路径就行了,这里可以使用Dijkstra算法。
4、如此,我们可以很容易地快速得出最短路径。 源码中含有第一部分预遍历的实现。但是没有第二部分,第二部分寻路其实很简单了。 由于后来我决定采用第2种计算方法,即“分城市直接使用Dijkstra算法计算”。所以第一种算法也只是原理上实现,连测试都是没有的。感觉实现得挺有意思,便也没有删除这种算法。使用第二种算法的原因只是第一种算法大复杂了,一大堆的代码看得自己都头晕,便懒得去测试它了,在目前的数据规模下,也没有多大影响。
lua自带的时间函数好像只有秒,而必须附加库才能处理更精确的时间,所以不想去测这个这个执行时间了。但是我在使用的时候没感觉到任何延迟。一般这种数量级的数据处理应该是毫秒级的。100毫秒以下才是正常的时间。
而数秒种的遍历时间,那必然是直接使用数据库遍历数千个数据这样才能弄出来。 | 

 狗仔卡
狗仔卡 发表于 2014-1-29 13:52:33
发表于 2014-1-29 13:52:33
 提升卡
提升卡 沉默卡
沉默卡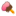 变色卡
变色卡 显身卡
显身卡